Bar charts are excellent visualizations to show the frequency of categorical data. Often, it is valuable to quickly create a frequency bar chart from a DataFrame of thousands of observations.
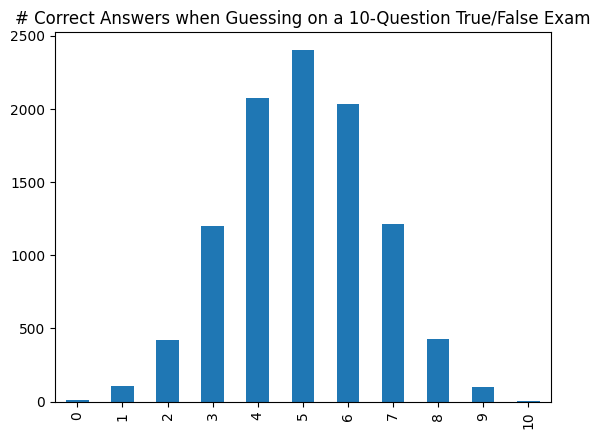
When visualizing complex data, such as a simulation of guessing on a true/false exam with 10 questions, we can quickly create a frequency bar chart of this data:
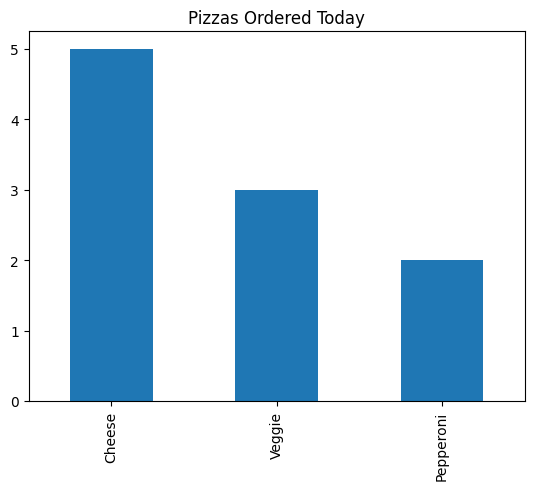
To understand the code to create a frequency bar chart, let's start with a simple DataFrame that stores data about each pizza that was ordered today:
The panda's function value_counts() counts the number of times each unique value appears in a column of a DataFrame. In our sample DataFrame, we can count the unique values of the pizzaOrder :
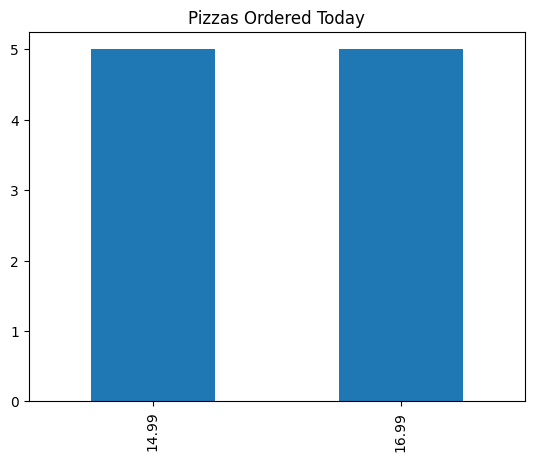
Similarly, a frequency bar chart of the different prices of pizza today:
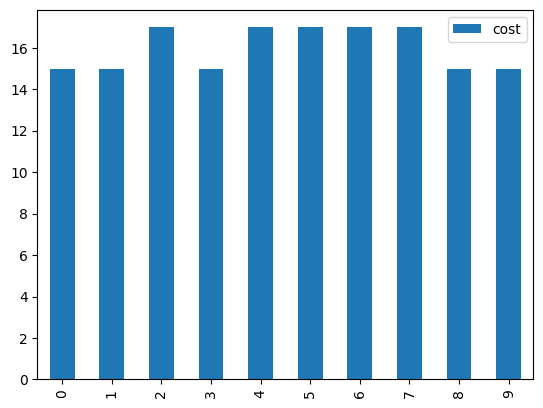
When working with numeric values, sorting the order in which the values appear in the bar chart becomes critical. There are two ways we might need to sort the data:
We'll explore an simulation to see the two ways to sor the data.
An extremely common application of frequency bar charts is in the exploration of simulation results. For example, the following code simulates taking an exam with 10 true/false questions and guessing on each question. The DataFrame stores the result of how many questions each of the 10,000 simulated students answers correctly when guessing randomly:
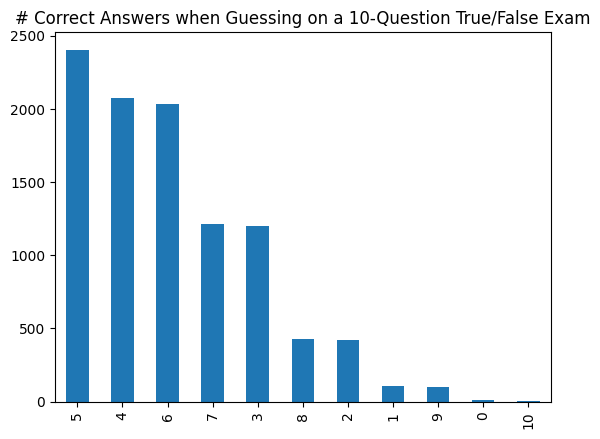
By default, value_counts() sorts the list of values by frequency so that the most common value appears first on the list returned by value_counts() and will display on the left-hand side of the chart.
It is common to want to sort by the category (stored in the index of the Series returned by value_counts() ). To create a bar chart sorted by the index, we add sort_index() after value_counts() . The result is that the data is now sorted by the category name instead of the frequency:
Data Science Discovery is an open-source data science resource created by The University of Illinois with support from The Discovery Partners Institute, the College of Liberal Arts and Sciences, and The Grainger College of Engineering. The aim is to support basic data science literacy to all through clear, understandable lessons, real-world examples, and support.